
A Hieronymus Bosch's painting of a chair

A Kazimir Malevich's painting of a chair

A photo of a chair on a beach

A low poly 3D rendering of a chair

A toy car in a box

A car on cyberpunk megapolis street

A vector graphic of a car

A halfway submerged car

A table in a workshop

A person drinking tea at a table

A coloring book illustration of a table

Claude Monet's painting of a table

A charcoal drawing of a lamp

An Art Deco poster of a lamp

A craftsman working on a lamp

A lamp under a tree

ShapeWords incorporates target 3D shape information within specialized tokens embedded together with the input text, effectively blending 3D shape awareness with textual context to guide the image synthesis process. Unlike conventional shape guidance methods that rely on depth maps restricted to fixed viewpoints and often overlook full 3D structure or textual context, ShapeWords generates diverse yet consistent images that reflect both the target shape’s geometry and the textual description. Our experimental results show that ShapeWords produces images that are more text-compliant, aesthetically plausible, while also maintaining 3D shape awareness.
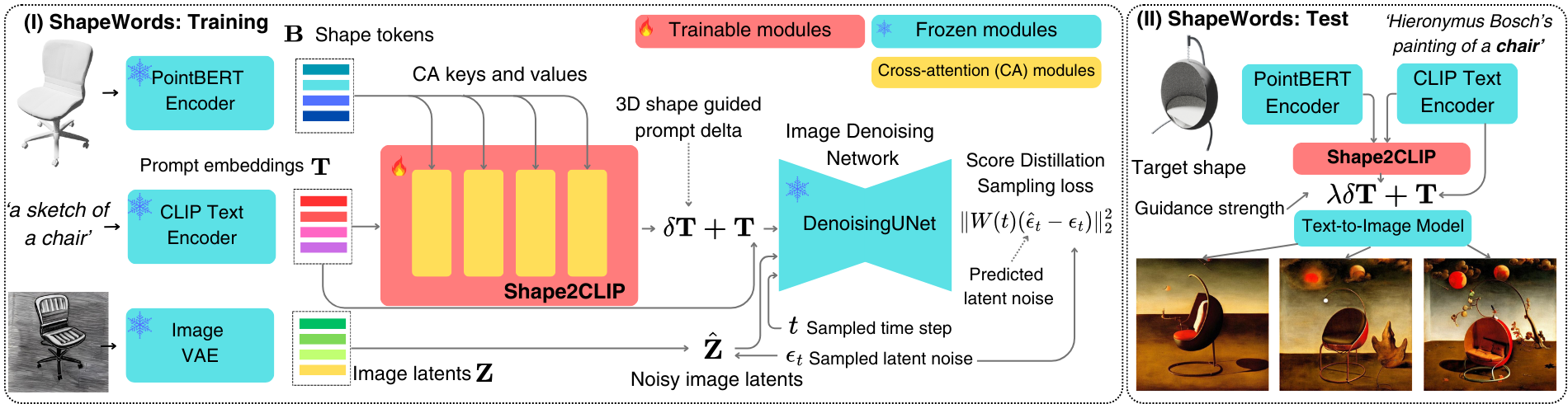
During training (I), ShapeWords takes as input triplet of a shape, a prompt, and an image. The shape S and prompt T are encoded using the shape encoder PointBert and the text encoder OpenCLIP, respectively. The resulting embeddings are passed through a cross-attention-based Shape2CLIP module, which produces a prompt residual δT to guide the source prompt toward the target geometry. This modified prompt is then passed as input to a Text-to-Image Denoising UNet along with sampled noisy image latents and time step t. The Shape2CLIP module is optimized via Score Distillation Sampling. During inference (II), the CLIP embeddings of the input prompt and the target embeddings of the test shape are passed through the Shape2CLIP module. Optionally, the desired strength of the shape guidance is controlled by the user parameter λ. For additional details about training data and implementation please refer to the paper.
Overall, ShapeWords presents an argument for soft structural guidance for text-to-image synthesis. In contrast to hard structural guidance like depth images, canny edges or renders, it allows users to explore variations of target geometries via manipulation of guidance strength λ. We illustrate this below. To change the target shape, use the top slider. To change guidance strength λ in increments of 0.2, use the bottom slider.
|

Target shape Guidance strength 0 1 |

Target shape Guidance strength 0 1 |
|

Target shape Guidance strength 0 1 |

Target shape Guidance strength 0 1 |
|

Target shape Guidance strength 0 1 |

Target shape Guidance strength 0 1 |

We compare ShapeWords with depth-conditioned baselines on compositional prompts that involve a target 3D shape alongside additional objects or humans interacting with it. Over-constrained depth conditioned baselines (e.g. ControlNet and Ctrl-X@60) ignore prompt composition. Under-constrained depth baselines (e.g. CNet-Stop@30 or Ctrl-X@30) stray too much from target geometry. ShapeWords provides non-superficial generalization to compositional prompts and strong adherence to target shape. We stress out that depth is only provided as input for baselines and ShapeWords does not use depth input.

We qualitatively compare the following strategies for guidance: adding the prompt delta δT to all prompt embeddings; adding it to only the object word embedding; adding it only to EOS token embedding; adding it to both EOS and object token embeddings (as done in the main paper). Prompts are: a charcoal drawing of chair
(top row), Hieronymus Bosch's painting of a chair
(middle row), a chair under a tree
(bottom row). Target shapes are shown on the left. Compared to modifying the object and EOS tokens, the all tokens
strategy produces over-smoothed images; the object only token
strategy struggles to incorporate stylistic cues from the text into geometry; and the EOS token
strategy struggles with preserving the target shape geometry.

Failure cases -- shape adherence. Our model struggles to generalize to shapes with complex fine-grained geometries (e.g. a lot of thin parts or lot of holes).
Prompts for the shapes are: a chair
(first two shapes); a lamp
(last three shapes). Target shapes are shown on the top.

Failure cases -- prompt adherence. Our model struggles to generalize to out-of-distribution prompts that require local adjustments of surface geometry. Prompts are: an origami of a chair
(top); a diamond sculpture of a chair
(middle); a hieroglyph of a chair
(bottom). Target shapes are shown on the right. Note that results for intermediate guidance strength suggest that our model can still generalize to such prompts to some extent. We suspect that this issue could potentially be alleviated by using more diverse training data.
@misc{petrov2024shapewords,
title={ShapeWords: Guiding Text-to-Image Synthesis with 3D Shape-Aware Prompts},
author={Dmitry Petrov and Pradyumn Goyal and Divyansh Shivashok and Yuanming Tao and Melinos Averkiou and Evangelos Kalogerakis},
year={2024},
eprint={2412.02912},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2412.02912},
}