
|

|

|

|

|

|

|
|

|

|

|

|

|

|

|

|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
We introduce GEM3D — a new deep, topology-aware generative model of 3D shapes.
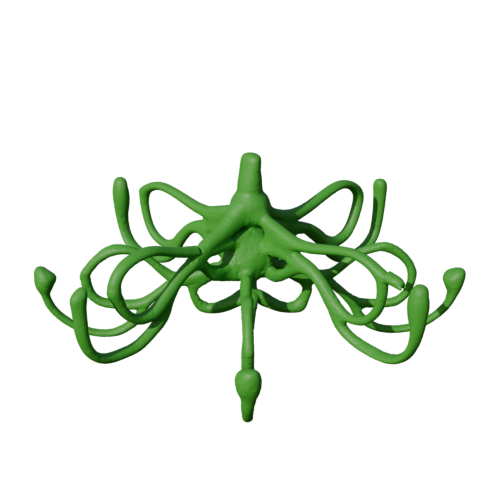
The key ingredient of our method is a neural skeleton-based representation encoding information on both shape topology and geometry. Through a denoising diffusion probabilistic model, our method first generates skeleton-based representations following the Medial Axis Transform (MAT), then generates surfaces through a skeleton-driven neural implicit formulation. The neural implicit takes into account the topological and geometric information stored in the generated skeleton representations to yield surfaces that are more topologically and geometrically accurate compared to previous neural field formulations.
We discuss applications of our method in shape synthesis and point cloud reconstruction tasks, and evaluate our method both qualitatively and quantitatively. We demonstrate significantly more faithful surface reconstruction and diverse shape generation results compared to the state-of-the-art, also involving challenging scenarios of reconstructing and synthesizing structurally complex, high-genus shape surfaces from Thingi10K and ShapeNet.
GEM3D architecture: starting with 3D Gaussian noise, first diffusion stage generates a point-based medial (skeletal) shape representation conditioned on a shape category embedding. Conditioned on this representation, our second diffusion stage generates latent codes capturing shape information around the medial points. In the last stage, our surface decoder decodes the medial latent codes and points to local neural implicit surface representations, which are then aggregated to create an output 3D shape.
Surface sampling conditioned on generated skeleton. From a practical point of view, one possibility of our method for users is to execute first diffusion stage, obtain various shape structures represented in their MATs, then select the one matching their target structure or topology goals more. Then the user can execute the second stage to obtain various shape alternatives conforming to the given structure. Above, we show a generated skeletons and diverse surfaces conforming to them. For example, our method can generate diverse lamp stands from a table lamp structure or chairs of diverse part thicknesses conforming to a particular chair structure.
Surface generation based on user-modeled skeletons. We asked two artists to draw the skeletons of completely fictional objects using 3D B-spline curves and patches. We uniformly sampled points from these skeletons and provided them as input to out method. As shown above, it was able to generate diverse and plausible surfaces conforming to these out-of-distribution skeletons.
|
|
|
|
|
|
|
|---|---|---|---|---|---|

|

|

|

|

|

|

|

|
|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|
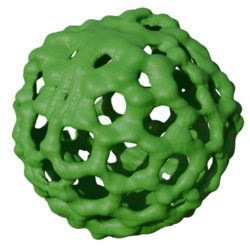
Point cloud reconstruction on Thingi10K. We test our and competing methods in a challenging out-of-distribution scenario: after training on ShapeNet, we test all methods on Thingi10K dataset. The Thingi10K shapes contain man-made objects that often possess highly complex topology (e.g., a large genus number). We note that the whole dataset is 10K test shapes, 4 times larger than the ShapeNet's test split and none of the Thingi10K shapes exists in ShapeNet. The vast majority of them do not even relate to any of the ShapeNet categories. Our model clearly outperforms the baselines -- the performance gap increases for topologically challenging shapes with higher genus (see the paper for quantitative results).
@misc{petrov2024gem3d,
title={GEM3D: GEnerative Medial Abstractions for 3D Shape Synthesis},
author={Dmitry Petrov and Pradyumn Goyal and Vikas Thamizharasan and
Vladimir G. Kim and Matheus Gadelha and Melinos Averkiou and
Siddhartha Chaudhuri and Evangelos Kalogerakis},
year={2024},
eprint={2402.16994},
archivePrefix={arXiv},
primaryClass={cs.CV}
}{kind=link}